
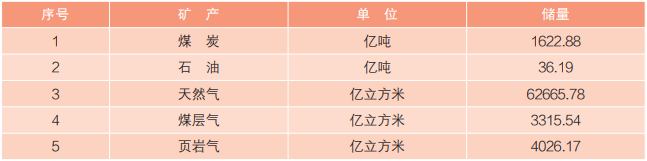
自然资源部晒出我国矿产资源“家底” 矿业绿色发展取得
人民网北京12月3日电 (记者杨曦)矿产资源家底数据是基本国情国力的重要组成部分。近日,自然资源部发布的《中
Random Forests is a popular machine learning algorithm used for both classification and regression problems. It is an ensemble learning method, meaning that it combines the predictions of multiple individual decision trees to make a final prediction. Random Forests is known for its accuracy, stability, and ease of use, making it a popular choice for many data scientists.
So what are Random Forests and How do They Work?
Random Forests is a type of decision tree algorithm that creates a collection of decision trees and combines their predictions to make a final prediction. In Random Forests, each decision tree is trained on a random subset of the data, and the final prediction is made by combining the predictions of all the trees in the forest.
 (资料图片)
(资料图片)
The idea behind Random Forests is that by combining the predictions of many individual trees, the algorithm can reduce overfitting, increase stability, and improve the accuracy of the final prediction.
How Random Forests Works
The process of creating a Random Forest can be divided into several steps:
Random Subsampling: The first step in creating a Random Forest is to randomly subsample the training data. This is done by selecting a random subset of the data, which will be used to train each individual tree in the forest.
Tree Generation: The next step is to generate the individual trees in the forest. Each tree is generated using a decision tree algorithm, such as C4.5 or ID3. The decision tree is trained on the subsampled data and uses the information gain or entropy to determine the best split at each node.
Feature Selection: When training each decision tree, only a random subset of the features is considered for each split. This helps to reduce overfitting, as it prevents the tree from becoming too complex and memorizing the training data.
Prediction: The final step is to make a prediction for a new data point. This is done by sending the data point through each tree in the forest, and combining the predictions to make a final prediction. In classification problems, the majority vote of all the trees is used to determine the final class. In regression problems, the average of the predictions from all the trees is used.
Advantages of Random Forests
Random Forests has several advantages over other machine learning algorithms, including:
Accuracy: Random Forests is known for its accuracy, making it a popular choice for many data scientists. The algorithm can handle both linear and non-linear data and is able to capture complex relationships between the features.
Stability: Random Forests is stable, meaning that it is less likely to be affected by outliers and noisy data. This is because the algorithm combines the predictions of multiple trees, which helps to reduce the impact of any individual tree that may be affected by outliers.
Ease of Use: Random Forests is easy to use, as it requires very little tuning of the parameters. The algorithm is also easy to interpret, as the individual trees in the forest can be visualized to see how the decision was made.
Disadvantages of Random Forests
Despite its many advantages, Random Forests also has some disadvantages, including:
Computational Expense: Random Forests can be computationally expensive, as it requires generating multiple trees and combining their predictions. This can make the algorithm slow for large datasets.
Overcomplexity: Random Forests can become overcomplex, as it generates many trees. This can make it difficult to interpret the results and understand how the final prediction was made.
Conclusion
Random Forests is a popular machine learning algorithm used for both classification and regression problems. The algorithm is an ensemble learning method, meaning that it combines multiple decision trees to make predictions. This combination of decision trees helps to reduce overfitting and improve the accuracy of the predictions. The algorithm also provides valuable feature importance information, allowing us to understand which features are the most important in making predictions. Despite its many benefits, Random Forests can be computationally expensive and may struggle with highly imbalanced datasets. However, it remains a widely used and powerful machine learning algorithm for a variety of problems.
Copyright 2015-2022 太平洋艺术网 版权所有 备案号:豫ICP备2022016495号-17 联系邮箱:93 96 74 66 9@qq.com